Schedule Pipeline Processing¶
Deliver analytic insights to your customers on a predictable cadence.
Just as DataOps recommends automating tests, it is a best practice to automate production processing to give DevOps personnel more time for innovation, to provide regular operational metrics for analysis and improvements, and to increase customer trust with reliable deliveries.
A production pipeline that gets regular data inputs from vendor files or regular code updates from development deployments can be scheduled very easily to run via a cron job. DataOps borrows the concepts of continuous delivery or continuous deployment (CD) from DevOps.
In real-world data analytics, the production pipeline and development pipeline are not separate. The same team may be responsible for both. The same assets are leveraged. Events in one affect the other. DataOps breaks down the traditional barriers and captures the interplay between the two workflows and between data and code, so that cycle time, quality, and creativity can all be improved.
In this way, DataOps also borrows the continuous integration (CI) approach by automating the orchestration and testing of both new data in production and new code from a development pipeline. Together CI and CD resolve the main constraint hampering Agile development. Before DevOps, Agile created a rapid succession of updates and innovations that would stall manual integration and deployment processes. With automated CI and CD, DevOps has enabled companies to update their software many times per day.
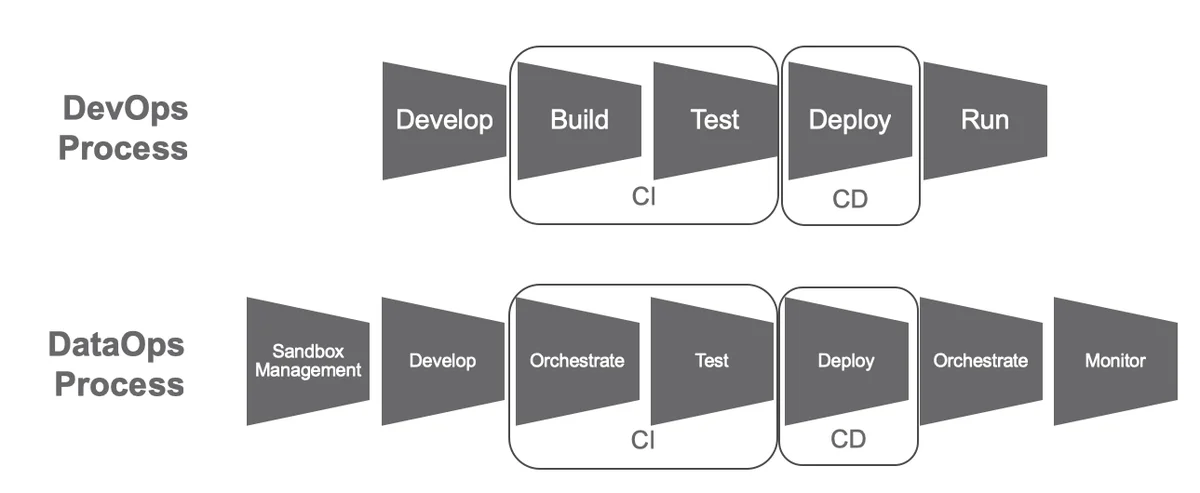
In the DataOps CI/CD process, orchestration occurs twice. First, DataOps orchestrates the data factory—a pipeline process with many steps. This orchestration involves initializing tools, controlling the execution of the steps, traversing the directed acyclic graph (DAG), and handling exceptions. For example, the orchestrator software might create containers, invoke runtime processes with context-sensitive parameters, transfer data from stage to stage, and monitor pipeline execution. Second, DataOps orchestrates the data operations. This is the orchestration that coordinates testing, monitoring results over time, and statistical process control.
The goal of DataOps is to create analytics in the development environment, advance them into production, receive feedback from users, and then continuously improve through further iterations. Running this cycle on a schedule makes it an efficient and dependable data and analytics factory.